Decathlon
The decathlon is composed of ten different events. So how do they calculate an overall winner? The simplest way would be to use z-scores. In an event, one would calculate all competitors' average distance for a field event (or time for a track event) and the standard deviation of distances (or times). A specific decathlete's z-score for a field event would be:
Thus, above average distances would have positive z-scores. The reverse calculation, average - performance, would be used for track event times so that below average times have positive z-scores also. Then, each decathlete's z-scores for all ten events would be averaged to produce his final, cumulative decathlon score. That is it. No fuss. No complication.
Of course, the decathlon's organizers want scores to compare from year-to-year. The averages and standard deviations used to calculate z-scores could be based on all recorded competitors, not just the current group of competitors. Of course, if the organizers did that, then the averages and standard deviations would always change (slightly), so old scores would have to be re-computed. This seems like a rather small inconvenience. The z-score is a simple way to rank, allowing one to compare performances in different events, by comparing performances relative to the average (and standard deviation) in each event.
Instead, the decathlon is scored using benchmarks. First, organizers set the benchmark time or distance in an event based on the performance an untrained schoolchild could muster. Second, the difference between an athlete's performance and the set benchmark is calculated. Third, this difference is raised to a set exponent greater than 1:
The exponent is set such that a world record time (or distance) in that event would yield a score of about 1000 points. The benchmark and exponent must be set differently for each event. As a further consideration, the choice of an exponent greater than 1 was intentional; the scoring is supposed to be non-linear or "progressive." A tenth of a second improvement to an already fast time increases a score by more points than making the same tenth of a second improvement to a middling time. The rationale is that the human body starts to reach physiological limits.
However, this kind of benchmarked scoring system opens the door to tinkering with the benchmark and exponent. This is why the formulas have been revised at least 6 times in 100 years, an average of about once every 17 years. This is less stable than simply re-calculating old z-scores. Furthermore, the scores are not balanced:
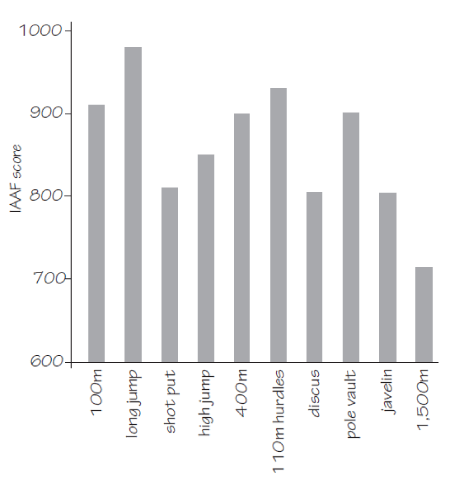
These are average scores in each event from the top 100 decathletes (http://nrich.maths.org/8346).
In some events, either the benchmark is too loose or the exponent is too high because the scores are too high, e.g., the long jump. Why is it a problem that some events' average scores are too high? Consider it this way: Say a decathlete performs at average in every event and say he can magically improve his performance by one standard deviation in one event. Which event does he choose? Under a z-score system, it does not matter since one standard deviation above average is scored the same no matter what the event. Under the benchmark system, his choice is to improve in the long jump. The average long jump of decathletes is already considered "excellent," so any improvements here are rewarded very highly. He should not improve his 1500 meter time, since the average is considered only "mediocre," so any improvement here is rewarded less highly. This is an odd outcome because the decathlete is supposed to be well-rounded, yet under the benchmark system, the best strategy for a decathlete is to improve in the event in which he is already "excellent."
In some events, either the benchmark is too loose or the exponent is too high because the scores are too high, e.g., the long jump. Why is it a problem that some events' average scores are too high? Consider it this way: Say a decathlete performs at average in every event and say he can magically improve his performance by one standard deviation in one event. Which event does he choose? Under a z-score system, it does not matter since one standard deviation above average is scored the same no matter what the event. Under the benchmark system, his choice is to improve in the long jump. The average long jump of decathletes is already considered "excellent," so any improvements here are rewarded very highly. He should not improve his 1500 meter time, since the average is considered only "mediocre," so any improvement here is rewarded less highly. This is an odd outcome because the decathlete is supposed to be well-rounded, yet under the benchmark system, the best strategy for a decathlete is to improve in the event in which he is already "excellent."
If all you want to do is rank decathletes, z-scores work the best. Although the decathlon benchmark system is similar in some ways to the z-scores, it represents a huge conceptual shift. The scores no longer just rank; no longer is the score showing how much better a specific decathlete did than the average decathlete. That information is now completely hidden to everyone but insiders. Instead, the benchmarked scores are supposed to be meaningful in another, more complicated way. There is a score representing perfection and a score representing amateurism. A z-score means: way below average, below average, average, above average, or way above average. A benchmarked score means: amateur, mediocre, good, excellent, or nearly perfect. This is a conceptual shift from a ranking system to a standards-based system. Standards are external judgments made about athletic performances before they even happen. It is conceivable every decathlete is said to be excellent; it also conceivable that even the winning decathlete is said to be mediocre.
Ranking students
If the goal is simply to rank students, then z-scores are simpler than letter grades. Given the average final percent score in a course and given the standard deviation of these scores, it would be easy to report out a z-score instead of a letter grade. I doubt people would go for negative scores, but the problem could be remedied by adding 4, e.g., a z-score of -3 is reported as "1". The z-scores could be rounded to one decimal place and limited in range to 0 to 8. (Almost no one would score more than 3 standard deviations above or below average anyway.) Let's call the z-score + 4 a "modified z-score."
If the z-scores are supposed to enable year-to-year comparisons, the average and standard deviation could be calculated for four or five years worth of students' percent scores in the course, not just the current group's. Looking at a z-score, there is no question how much above or below average a student is in the course. It is the clearest way to rank. This is unlike letter grades, where the student's relative rank is hidden. Some schools have started to include on a transcript the percent of students who earned A's in each course. However, this is a band-aid that still provides less information than the z-score.
To create an overall G.P.A., z-scores work as they would for the decathlon. A student's z-score for each English course would be averaged to create one English z-score, likewise for foreign language courses, for history/social studies courses, for math courses, and for science courses. (Averaging within an academic department first is necessary because not all students take all five subjects every year.) These five z-scores -- representing the high school academic pentathlon, as it were -- would be averaged to produce a final G.P.A. z-score. This G.P.A. z-score could be used to decide which students make dean's list, which student is the valedictorian, etc.
With z-scores, excellence in each subject is treated equally. However, this is not true with letter grades; the calculations are throw off if an entire department gives too many A's -- just like the long jump benchmark errors throw off the decathlon calculations. To illustrate this problem with letter grades, say that at Example High School, the English department hands out A's like candy but the math department gives few A's. Excelling in English at Example H.S. would do very little to distinguish a student's grade of A+ from the average English grade of A-, so an outstanding English student would gain only a little on his G.P.A. above the average G.P.A. However, excelling in math at Example H.S. could easily distinguish a student. If the average math grade is a B-, a student earning greater than a B+ has helped her G.P.A. more than the excellent English student did help his. One might say that it might be as difficult to earn a B+ in math as it is to earn an A+ in English at Example H.S., so these should be rewarded equally -- but we have no idea from letter grades how much above average these respective efforts are! We would merely be guessing.
(Of course, the biggest issue is not comparing achievement between departments using z-scores. Very few people would object to the parity z-scores would bring. The biggest issue would be comparing achievement within a department. Specifically, people would object to equating a modified z-score of 5 in a regular section to a 5 in an honors section of the same course. It seems like the regular section score should be discounted. There is one best solution: give a common exam or common assessments, and make the z-score based on the average and standard deviation for ALL students in that course, no matter what the level, regular or honors. Thus, a student above the regular course students' average might not receive a 5 but perhaps a 3, indicating that this student is below the overall average, even though he is above the regular section's average. This is a bit into the weeds and beside the point because letter grades face the same problem.)
Grades as standards
That was my plug for z-scores. On the other hand, letter grades are supposed to mean something, not just rank the students. Here is my breakdown:
- A+: student did impeccable work; he or she should take harder courses in this subject
- A and A-: student did excellent or above average work in all areas of course
- B+ and B: student did solid work, performing near the average in all areas of course
- B- and C+: student did acceptable but below average work; he or she may have serious gaps in certain content areas
- C and C-: student did work well below average; he or she needs serious help to pass the next course in this subject
- D: student can earn credit for effort, but he or she should repeat this course
- F: no credit
If you want to quibble with the meaning I have assigned to the letter grades -- maybe you think a C+ should be the average grade -- it is your prerogative. But this would just prove that the meaning of letter grades is, ahem, different from school to school.
I remember reading in Robert Marzano's book on grades that, when one norms across S.A.T. scores, very similarly-skilled children do earn C's at good schools but A's at bad schools. A grade of B- in English at a good school may show that a student is a solid reader, capable of pulling out meaning and seeing literary devices, able to string solid sentences together, and struggling a bit with organizing a full essay. A grade of B- in English at a bad school may mean that a student struggles with reading basic texts, misunderstands a lot of the writer's meaning, and has trouble putting together a coherent sentence. This is a far worse problem than the decathlon has; at least the times and distance are measured objectively.
So we should stop and ask, "What are we trying to do with letter grades?" Is there a benefit to attaching a standards-based meaning, even we know those standards vary from school to school? What is our purpose to giving letter grades, above and beyond what we could do with simple z-scores. Let's look at a couple possible purposes.
College admissions
We all know that college admissions are the cart driving the horse here. But I cannot imagine that college admission officers really need letter grades per se; the z-score system would work just fine for them. Of course, one cannot directly compare z-scores between two different schools for the same reason one cannot compare letter grades. However, I am sure that college admission officers have all sorts of statistical voodoo they do to norm the letter grades, using S.A.T., A.P., and other standardized testing scores, which they could also do with z-scores. So -- do college admissions officers find anything useful about letter grades that is lacking from z-scores?
I have heard class rank is the best predictor of college success because it reveals which students in a school are diligent, hardworking, and responsible, and these characteristics are far, far more important than content knowledge or academic preparedness. Letter grades kind of get at these characteristics better than z-scores because each teacher helps decide where to draw the line between an A- and B+ or between a B- and C+. A teacher looks at a test and says, "Gosh, I made this too hard. These four kids really do deserve A's but only got 80%." And teachers decide to toss out certain questions or give a retake if the results are too low. With a letter grade, there is a teacher's stamp of approval that the A student is truly diligent and hardworking. Z-scores are simply numbers, no meaning attached. This is why colleges like letter grades, but perhaps what they would like most would be a two-score system: a z-score to indicate academic achievement and a letter grade that reflected effort alone. Current letter grades attempt to do both and make the situation less clear, but splitting them lets the college admission officers know about achievement but also, and maybe more importantly, effort.
Parents, the school and district
Would the two-score system work for parents, the school, and district? The school and district need to know which children have not passed a course and need to repeat it, so an academic achievement score is a necessity. But for other placements -- whether a child should be in an honors or a regular section – an achievement score alone is unhelpful. Did a child get a B because she works hard but struggles with the concepts? In this case, an honors course seems a poor fit. Did a child get a B because he is brilliant with the concepts but is unable to complete assignments on time? And now that child has been diagnosed and is being treated for ADHD? An honors course might be appropriate. The two-score system would actually be quite helpful in making these kinds of judgments.
Does the two-score system communicate useful information to the parent? At parent-teacher conferences, I always let parents know the child's letter grade -- and their immediate questions are, "So is she doing the homework? Paying attention in class?," or, "Is her work careful and thoughtful or careless or shallow?" Parents are rightfully concerned with habits, and they would want better information than just an achievement score. The two-score system would better for parents than an achievement score alone or the current, murky letter grade.
Students and teachers
Perhaps periodically (once a quarter), the achievement score might help a student understand how he is doing: "You're struggling; seek extra help," versus, "Keep up the good work!" But at the level of a single quiz or test, an achievement score is unhelpful. A student needs to look over his work carefully to see what he understands and what he does not, and research has shown that if there is a score on top, he looks at that and not much else. In other words, a score can undermine meaningful feedback. The effort grade is also not particularly interesting to the students either. They know how much effort they are putting in.
Likewise, the two-score system is not especially helpful to teachers either. As a teacher, effort grades do not let me know how well my students are learning a topic. Neither does the achievement score: If all my students bomb a test, I can still rank them using a z-score, and top one might still have a solid z-score. As a teacher, what I need to do is look at their work and decide whether it meets an acceptable standard on that topic.
What teachers and students need is richer information about the content and skill areas in which a student is excelling or struggling. That is what real standards-based grading could do: For every separate area, each student could be rated as "not meeting the standard," "meeting the standard," and "exceeding the standard." There could be different areas for each course. In a math course, there are the big five skills: (1) arithmetical and algebraic skills; (2) intuition for new concepts; (3) problem-solving skills, e.g., both the ability to use concepts flexibly and the ability to follow through a plan; (4) logic, e.g., understanding definitions, proofs, and the like; and (5) communication skills. These are, in my experience, not independent but not highly correlated either. If a student is strong at logic, for example, she will often be good at problem solving -- but not always. I have seen enough exceptions to not treat this as a rule. It is worth tracking all five separately. There are all the different content skills as well, such as being able to do X, Y, or Z kind of problem. The content standards should be based on district, state, or national curriculum guidelines.
I imagine standards-based grading working like this. Upon received a marked test back, the student might see a list of the skill and content areas covered on the test. For each one, the student would see a rating. "Arithmetic/algebra: exceeding the standard; no careless errors. Problem solving: meeting the standard; missed some key application questions. Linear equations: not meeting the standard; several serious errors." He could flip through the marked test to see these mistakes and know what he needs to study for the next assessment. It is granular enough to allow meaningful feedback but not overwhelming. And I would resist giving any overall score or letter grade until, at the very least, the student did corrections and understood his errors.
For the teacher's part, the standards grades would reflect her evaluation in each area of each test. Of course, the percent score would still be recorded for the achievement score, and most grade programs also allow separate standards-based grades to be recorded for each test in addition to a percent score. I have seen people develop very complicated ways to turn these standards grades into overall letter grades, but why bother? My purpose in giving standards grades is to give students more effective feedback (and to have more specific knowledge of my students), not to make their letter grade fairer.
Here is the other complication: standards may not always line up with a percent grade. If a content area is basic, meeting the standard might mean getting 90%. If the content area is complicated, meeting the standard might mean getting 75%. As one colleague put it, "If I write three questions that really require some problem-solving skills, an excellent student might get two and just not see how to do the third. And that's OK." The point is that meeting or exceeding a standard does not translate back into a percent grade. Keep them separate.
Conclusion
There is my simple grading solution: (1) give modified z-scores instead of letter grades to record achievement in a course; (2) give separate letter grades for effort and diligence; and report these two on transcripts. Also, (3) give standards grades in major skill and content areas as interim feedback to students. This last information would also be useful for parent-teacher conferences and to pass along to the next year teachers. It could be recorded with the student's grade and used internally but not reported out to colleges. Alright, it is not that simple a system, but it would work a lot better than the current one-size-fits-all letter grade. The primary purpose of a grade is to communicate information about a student's performance, so why would we assume that each audience needs exactly the same information? It is a lot more complicated than the decathlon.
Epilogue: Here is a great article on standards-based grading. And another one.
